The Benefits of Asynchronous Programming
- TECH BLOG
- Christian Carijutan
A deep dive into Asynchronous Processing
Dealing with long time processing for a single transaction or waiting too long when downloading something from an application and causing an upstream timeout error due to heavy loads makes the server slow to respond to requests.
We decide to use asynchronous processing.
Our existing process downloads CSV files from the server, including parsing, extracting records from the database, generating it to CSV, and running on a single thread process. In that process, we encountered an upstream timeout error every time the records got bigger. Our first approach is still to do it all synchronously but optimize the parsing and extracting of records, but still, an upstream timeout error occurs when the records get bigger.
In that situation, we tried to find another solution to solve the problem, then found the asynchronous processing and started looking at it.
Flow diagram before the asynchronous process
Dive into asynchronous programming
There are many different options for asynchronous programming, and this is one of the subsets of libraries out there.
Redis
https://github.com/resque/resque
https://github.com/sidekiq/sidekiq
AWS S3 bucket
https://github.com/aws/aws-sdk-rails
To start, let’s set up our library to implement asynchronous processing:
Setting up Resque
Setup Redis
You’ll need Redis installed. Assuming you’re on MacOS and using Homebrew:
Follow the instructions in the notes to start Redis on boot, or start it manually with redis-server
Starting and stopping Redis in the foreground
To test your Redis installation, you can run the redis-server executable from the command line:

Setup Resque
Install Resque by adding gem ‘resque’ to the Gemfile and running bundle install

S3 Configuration
To set it up, go to config/storage.yml First, uncomment the section headed by Amazon. Next, fill in your bucket’s name and region. For my application, the Amazon section of config/storage.yml looks like this:
For details on configuring region and credentials, see the developer guide.

Now we can perform asynchronous programming by creating the controller and job for the export CSV controller.
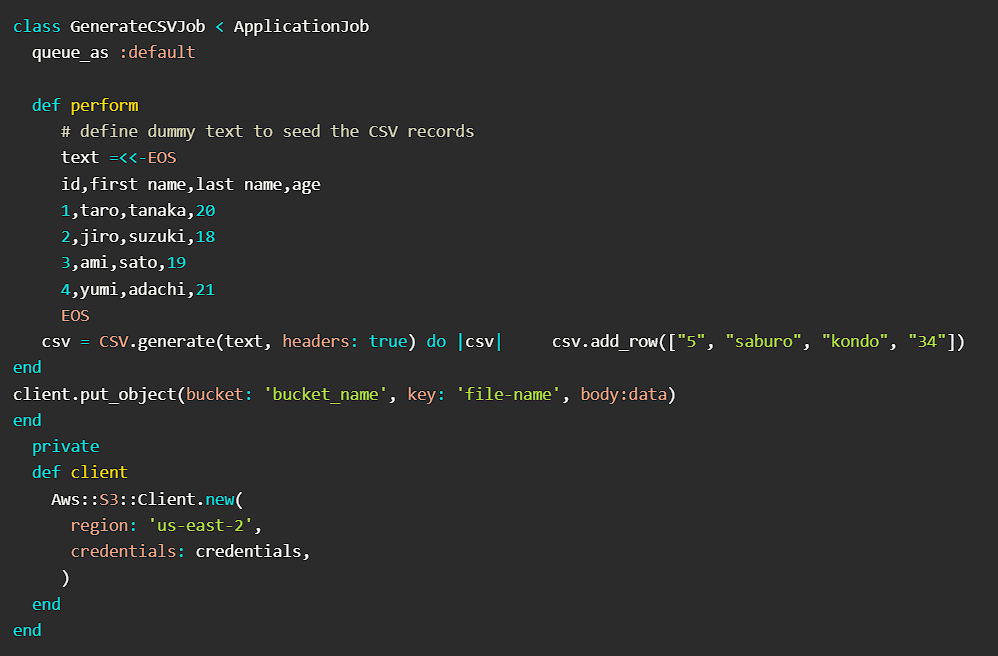
Writing Jobs
Each job should be a separate Ruby class that extends ApplicationJob and defines perform method.
Writing Controller
To run the execution of the job, initialize the instance class and call the method performed to the controller.

To understand asynchronous programming, see the flow diagram from request to response.
An application can handle heavy tasks without waiting for the result. When the result is ready, a separate call will request the server download or present it to the user and this is how asynchronous programming works in background processes.
Conclusions
If your application is designed for high/heavy load requests, it will require more than synchronous processes. There are several benefits associated with asynchronous programming, including:
- It provides an improved user experience. Asynchronous programming can improve the overall user experience since it helps systems run more efficiently. It helps reduce wait times, which often inconvenience the users.
- It helps improve an application’s performance. This type of programming can also help improve an application’s speed, the user interface of an application and make it easier for users to do their target.
- It’s possible to apply it to many programming languages. While asynchronous programming can make coding more complex, using the technique in various languages with different syntaxes is possible.